Chapter 3. Validating DocBook Documents
A key feature of XML markup is that you validate it. The DocBook schema is a precise description of valid nesting: the order of elements, and their content. All DocBook documents must conform to this description or they are not DocBook documents (by definition). The validation technology that is built into XML is the Document Type Definition or DTD. A validating parser is a program that can read the DTD and a particular document and determine whether the exact nesting and order of elements in the document is valid according to the DTD.
DocBook is now defined by a RELAX NG grammar and Schematron rules, so it is no longer necessary to validate with the DTD. In fact, it isn’t even very valuable since the DTD version doesn’t enforce many DocBook constraints. Instead, an external RELAX NG and Schematron validator must be used.
Validation is performed on a document after it has been parsed. It is possible for parsing errors to occur as well as validation errors (if, for example, your document isn’t well-formed XML). We’re going to assume that your documents are well-formed and not discuss XML parsing errors.
If you are not using a structured editor that can provide guidance on the markup as you type, validation with an external tool is a particularly important step in the document creation process. You cannot expect to get rational results from subsequent processing (such as document publishing) if your documents are not valid.
There are several free validators that will handle RELAX NG and Schematron, including Jing and MSV. For more detail about available tools, see Section 9, “XML Tools”.
1. ID/IDREF Constraints and Validation
In XML, attributes of type ID and IDREF
provide a straightforward cross-referencing mechanism. In DocBook, the
xml:id attribute contains values of
type ID, and the linkend attribute
contains values of type IDREF.
Within any document, no two attributes of type ID may have the same value. In addition, for any attribute of type IDREF, there must be one, and only one, instance of an attribute of type ID with the same value in the same document. In other words, you can’t have two elements with the same ID, and every IDREF must match an ID that exists somewhere in the same document.
Checking these constraints is not a core part of RELAX NG. If you
want RELAX NG to check them, you need to enable a set of DTD
compatibility
extensions. Unfortunately, the DTD compatibility
extensions do not work well with the DocBook grammar. However, because
DocBook uses xml:id for its ID
attribute, it’s not necessary to enforce the constraints with RELAX NG.
You can either tell your processor not to perform the DTD compatibility
extension checks, or ignore the warning messages that they produce. You
could also use Schematron to check ID/IDREF constraints.
2. Validating Your Documents
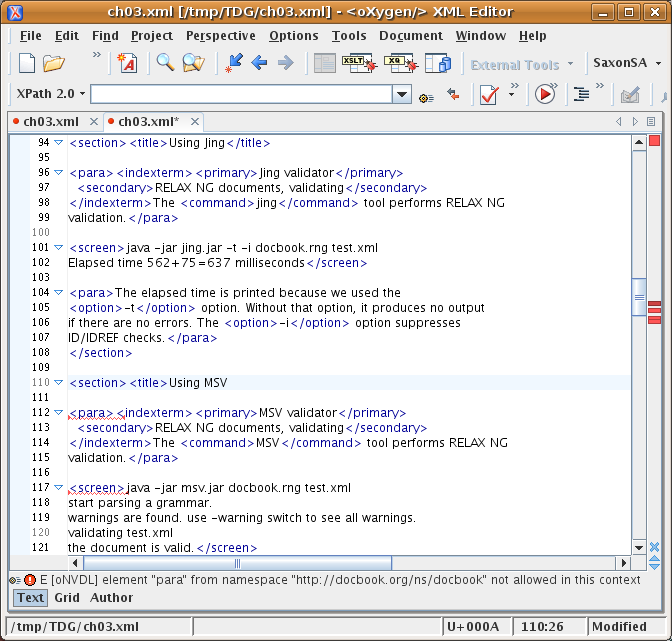
RELAX NG validation is supported natively in some editing
environments, such as <oXygen/> (see Figure 3.1, “<oXygen/> XML Editor validation”),
XMLmind, and Emacs (with
nxml-mode). <oXygen/> and XMLmind also support Schematron validation. There are also several
standalone validators—for example, Jing and Sun’s Multi-Schema Validator
(MSV).
If your documents make use of several namespaces (e.g., SVG and MathML embedded in DocBook), tools that support NVDL, Namespace-based Validation Dispatching Language NVDL, can greatly simplify complex validation scenarios.
3. Understanding Validation Errors
Every validator produces slightly different error messages, but most indicate exactly (at least technically1) what is wrong and where the error occurred. With a little experience, this information is all you’ll need to quickly identify what’s wrong.
In the rest of this section, we’ll look at a number of common errors and the messages they produce in MSV. We’ve chosen MSV because it generally produces informative error messages.
3.1. Character Data Not Allowed Here
Out-of-context character data is frequently caused by a missing start tag, but sometimes it’s just the result of typing in the wrong place!
1 |<chapter xmlns="http://docbook.org/ns/docbook" version="5.0">|<title>Test Chapter</title>|<para>|This is a paragraph in the test chapter. It is unremarkable in5 |every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test|chapter. It is unremarkable in every regard.|</para>|You can't put character data here.10 |<para>|<emphasis role="bold">This</emphasis> paragraph contains|<emphasis>some <emphasis>emphasized</emphasis> text</emphasis>|and a <superscript>super</superscript>script|and a <subscript>sub</subscript>script.15 |</para>|<para>|This is a paragraph in the test chapter. It is unremarkable in|every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test20 |chapter. It is unremarkable in every regard.|</para>|</chapter>
|java -jar msv.jar docbook.rng badpcdata.xml|start parsing a grammar.|warnings are found. use -warning switch to see all warnings.|validating badpcdata.xml|Error at line:10, column:7 of badpcdata.xml|unexpected character literal
You can’t put character data directly in a
chapter. Here, a wrapper element, such as
para, is missing around the sentence between the
first two paragraphs.
3.2. Misspelled Start Tag
If you spell a start tag incorrectly, or use the wrong namespace, the parser will get confused:
1 |<chapter xmlns="http://docbook.org/ns/docbook" version="5.0">|<title>Test Chapter</title>|<para>|This is a paragraph in the test chapter. It is unremarkable in5 |every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test|chapter. It is unremarkable in every regard.|</para>|<paar>10 |<emphasis role="bold">This</emphasis> paragraph contains|<emphasis>some <emphasis>emphasized</emphasis> text</emphasis>|and a <superscript>super</superscript>script|and a <subscript>sub</subscript>script.|</para>15 |<para>|This is a paragraph in the test chapter. It is unremarkable in|every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test|chapter. It is unremarkable in every regard.20 |</para>|</chapter>
|java -jar msv.jar docbook.rng misspell.xml|start parsing a grammar.|warnings are found. use -warning switch to see all warnings.|validating misspell.xml|Error at line:9, column:7 of misspell.xml|tag name "paar" is not allowed. Possible tag names are: <address>,<anchor>,|<annotation>,<bibliography>,<bibliolist>,<blockquote>,<bridgehead>,|<calloutlist>,<caution>,<classsynopsis>,<cmdsynopsis>,|<constraintdef>,<constructorsynopsis>,<destructorsynopsis>,<epigraph>,|<equation>,<example>,<fieldsynopsis>,<figure>,<formalpara>,|<funcsynopsis>,<glossary>,<glosslist>,<important>,<index>,|<indexterm>,<informalequation>,<informalexample>,<informalfigure>,|<informaltable>,<itemizedlist>,<literallayout>,<mediaobject>,|<methodsynopsis>,<msgset>,<note>,<orderedlist>,<para>,|<procedure>,<productionset>,<programlisting>,<programlistingco>,|<qandaset>,<refentry>,<remark>,<revhistory>,<screen>,<screenco>,|<screenshot>,<section>,<section>,<segmentedlist>,<sidebar>,|<simpara>,<simplelist>,<simplesect>,<synopsis>,<table>,<task>,|<tip>,<toc>,<variablelist>,<warning>
Luckily, these are usually easy to spot, unless you accidentally spell the name of another element. In that case, your error might appear to be out of context.
3.3. Out-of-Context Start Tag
Sometimes the problem isn’t spelling, but rather placing a tag in the wrong context. When this happens, the validator tries to figure out what it can add to your document to make it valid. Then it tries to recover by continuing as if it had seen what it just added. Of course, this may cause future errors:
1 |<chapter xmlns="http://docbook.org/ns/docbook" version="5.0">|<title>Test Chapter</title>|<para>|This is a paragraph in the test chapter. It is unremarkable in5 |every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test|chapter. It is unremarkable in every regard.|</para>|<para><title>Paragraph With Inlines</title>10 |<emphasis role="bold">This</emphasis> paragraph contains|<emphasis>some <emphasis>emphasized</emphasis> text</emphasis>|and a <superscript>super</superscript>script|and a <subscript>sub</subscript>script.|</para>15 |<para>|This is a paragraph in the test chapter. It is unremarkable in|every regard. This is a paragraph in the test chapter. It is|unremarkable in every regard. This is a paragraph in the test|chapter. It is unremarkable in every regard.20 |</para>|</chapter>
|$ java -jar msv.jar docbook.rng context.xml|start parsing a grammar.|warnings are found. use -warning switch to see all warnings.|validating context.xml|Error at line:9, column:14 of context.xml|tag name "title" is not allowed. Possible tag names are: <abbrev>,<accel>,|<acronym>,<address>,…,<varname>,<warning>,<wordasword>,<xref>
In this example, we probably wanted a
formalpara so that we could have a title on the
paragraph. But note that the validator didn’t suggest this alternative.
The validator only tries to add additional elements, rather than rename
elements that it’s already seen.